VidMuse: A Simple Video-to-Music Generation Framework with Long-Short-Term Modeling
Accepted to CVPR 2025
Abstract
In this work, we systematically study music generation conditioned solely on the video. First, we present a large-scale dataset comprising 360K video-music pairs, including various genres such as movie trailers, advertisements, and documentaries. Furthermore, we propose VidMuse, a simple framework for generating music aligned with video inputs. VidMuse stands out by producing high-fidelity music that is both acoustically and semantically aligned with the video. By incorporating local and global visual cues, VidMuse enables the creation of musically coherent audio tracks that consistently match the video content through Long-Short-Term modeling. Through extensive experiments, VidMuse outperforms existing models in terms of audio quality, diversity, and audio-visual alignment. The code and datasets will be available at https://github.com/ZeyueT/VidMuse/
Demo Video
Video-to-Music Generation
V2M Dataset
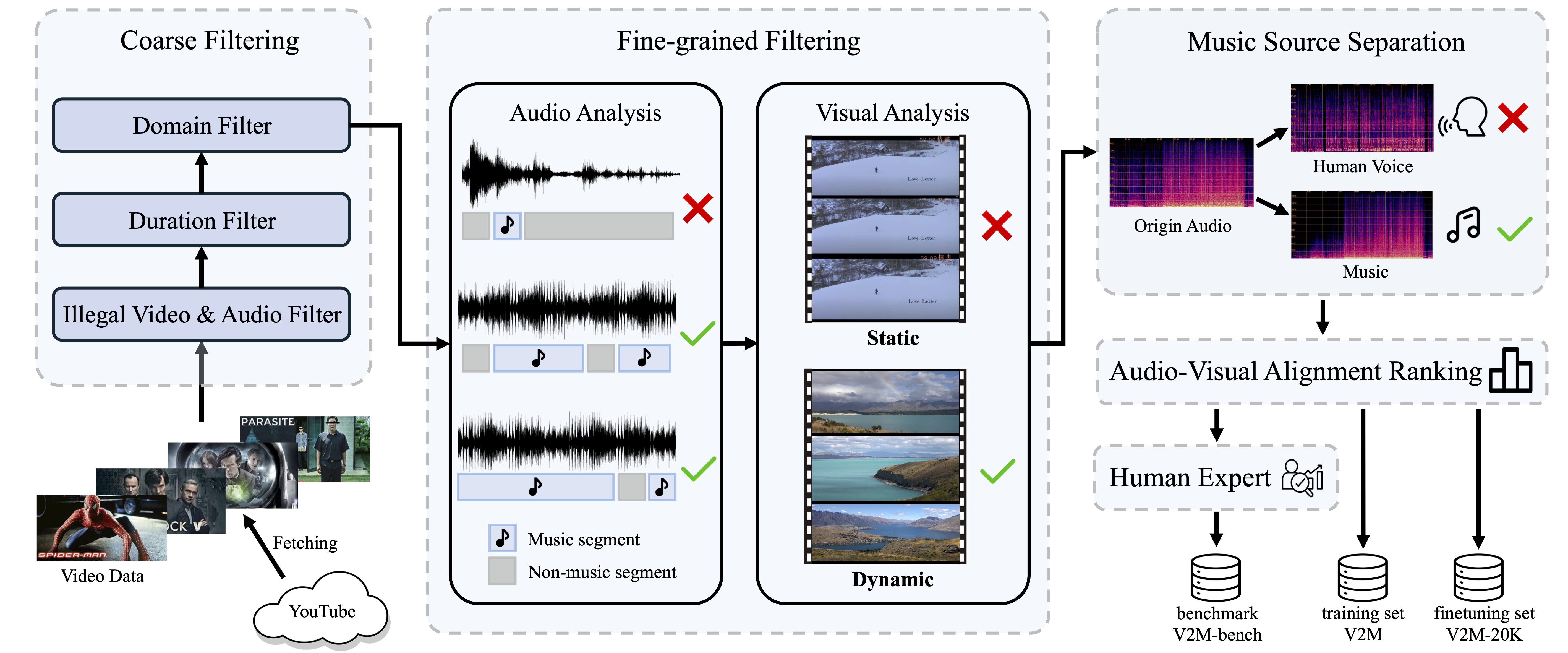
The Pipeline of Dataset Construction
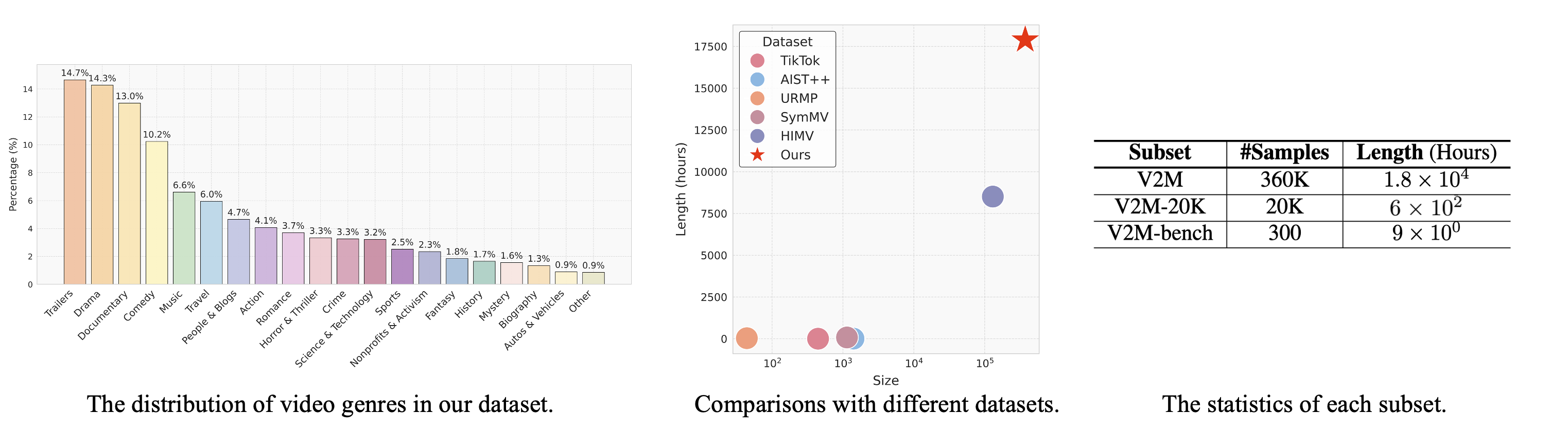
Data Statistics
Method
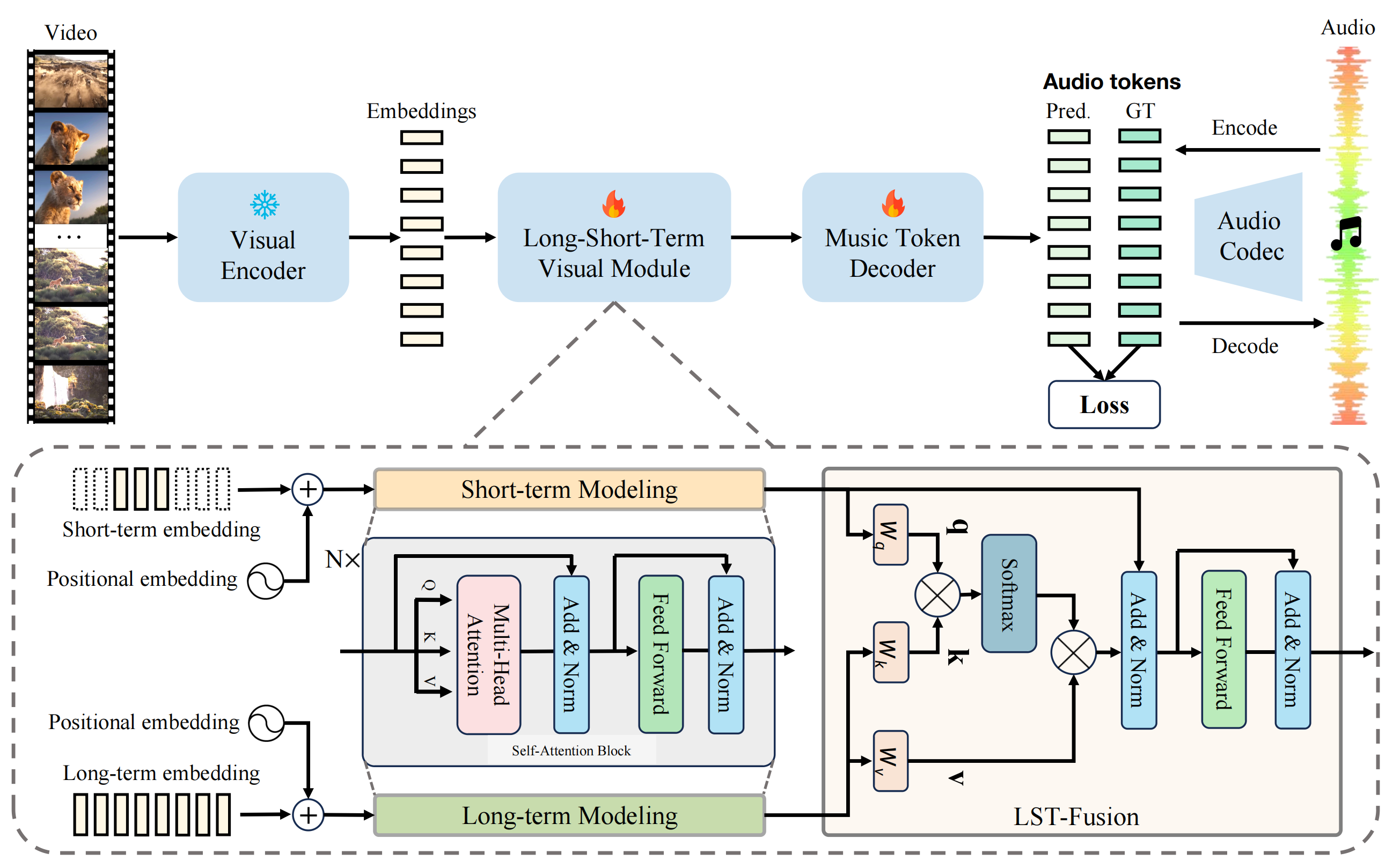
The overview of our proposed VidMuse.
Experiments
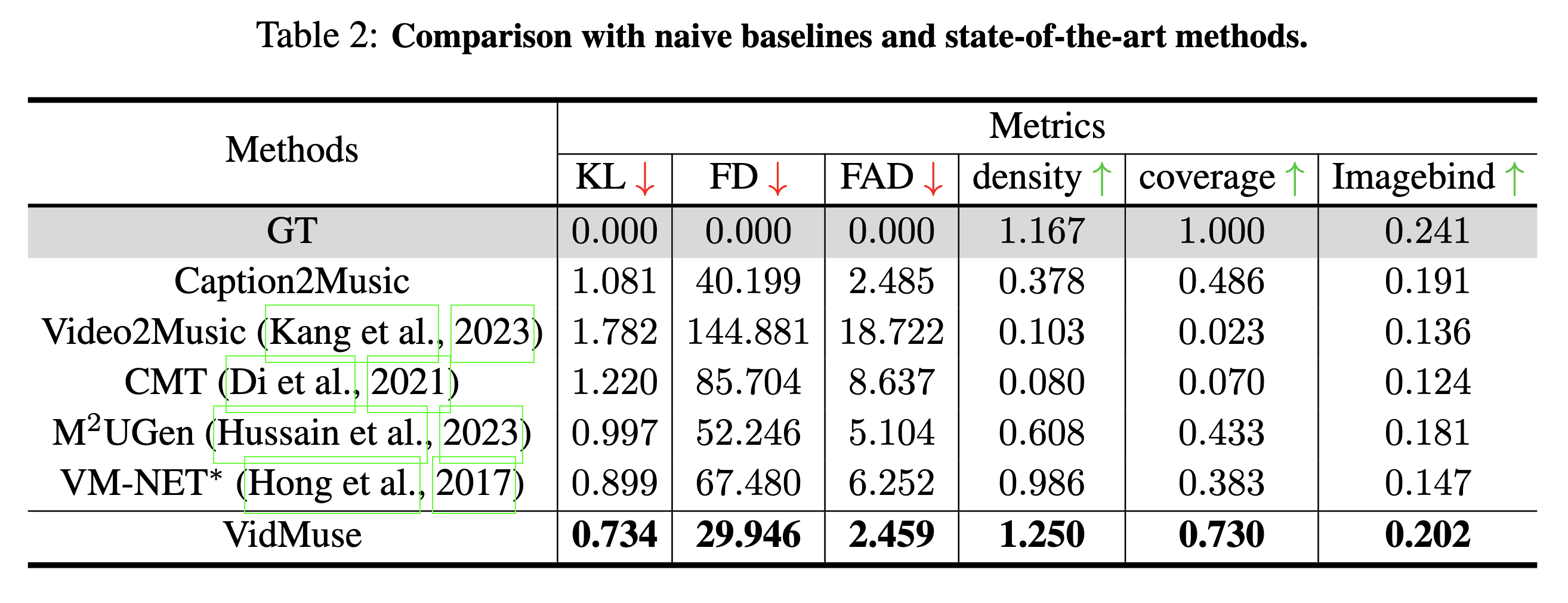
Main Results
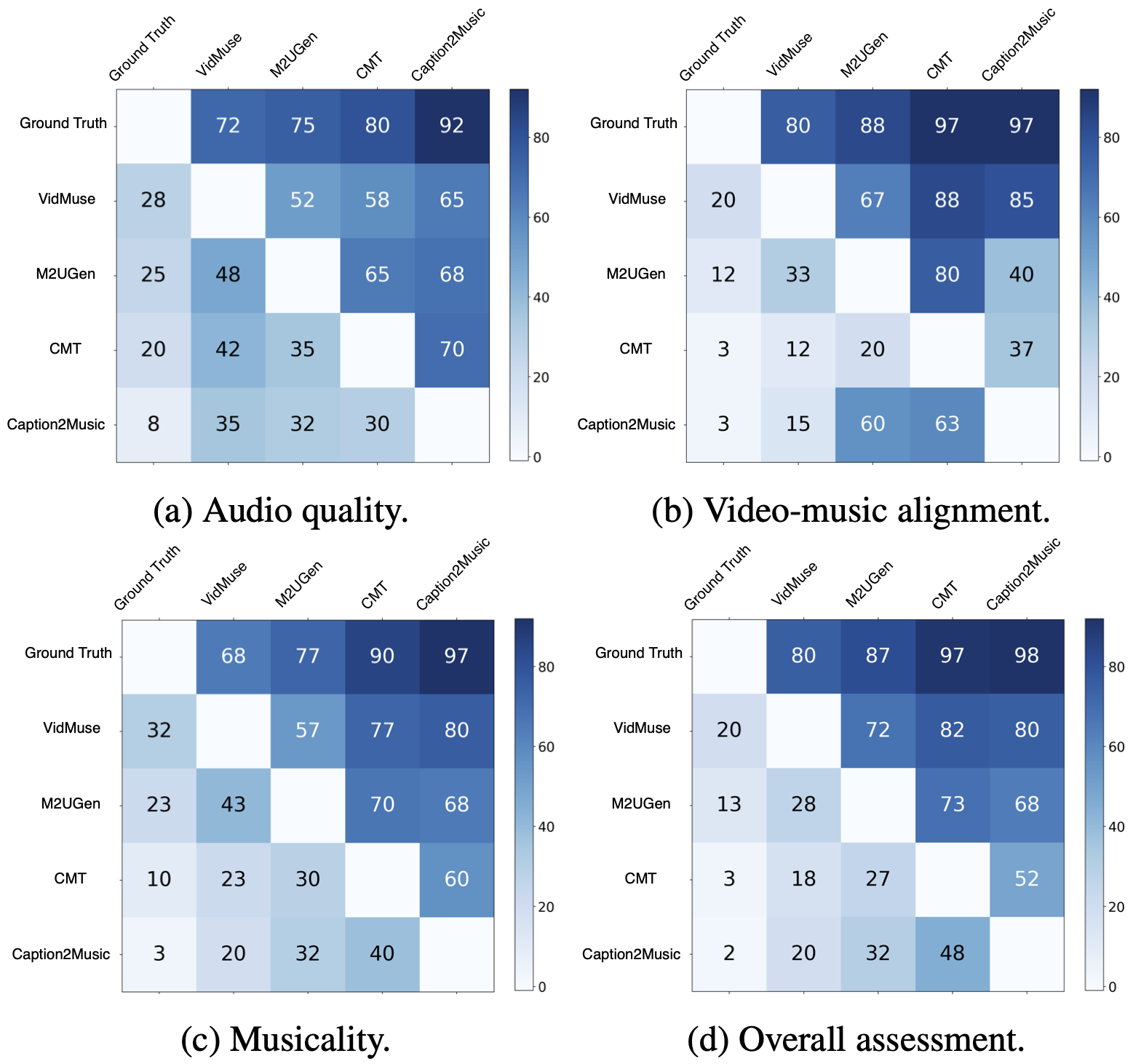
User Study
BibTeX
If you find our work useful, please consider citing:
@article{tian2024vidmuse,
title={VidMuse: A Simple Video-to-Music Generation Framework with Long-Short-Term Modeling},
author={Tian, Zeyue and Liu, Zhaoyang and Yuan, Ruibin and Pan, Jiahao and Huang, Xiaoqiang and Liu, Qifeng and Tan, Xu and Chen, Qifeng and Xue, Wei and Guo, Yike},
journal={arXiv preprint arXiv:2406.04321},
year={2024}
}